Data and Code Availability Policy: Frequently Asked Questions
- Administrative Questions
- Is there a cost to using the AEA Data and Code Repository?
- Should I upload the manuscript, or the online appendix?
- Do I keep the copyright on materials I upload to the AEA Data and Code Repository?
- Licensing
- What to Expect
- Will my code be run by the AEA?
- How does the AEA test that the data and code is reproducible and replicable?
- Uploading
- Can I use other archives or data repositories?
- My data is made available on Dropbox, OneDrive, Sugarsync, or my personal website. Do I need to do anything else?
- We already use git, svn, GitHub, GitLab, or BitBucket, etc. Do you facilitate integration of existing version-controlled code to the AEA repository? Or is there planned functionality for linking out directly to such projects where they can be found online?
- How do I cite my data and code deposit?
- Should my data and my code be in the same deposit?
- Software Questions
- Some econometrics papers might be accompanied by a software package, for example, R or Stata (perhaps published on CRAN or SSC). What about surfacing references to associated packages more prominently?
- Do you support Docker, Jupyter, etc.?
- Restricted-Access Data
- My data has identifiable person or firm/establishment information, and I want to control who has access. Can I use the AEA Data and Code Repository?
- I have been told by the Data Editor to remove PSID data from my submitted materials. What do I do?
- Access to the data I used is restricted. Surely you won’t be able to run the code. Is that a problem?
- I use confidential data. I am allowed to provide the data to the Data Editor for the purpose of replication, but you are not allowed to publish the data. How do I proceed?
Administrative Questions
Is there a cost to using the AEA Data and Code Repository?
No.
Should I upload the manuscript or the online appendix?
No, you should only upload data and code. Draft or final manuscript or appendix files should be sent to the editorial office.
Do I keep the copyright on materials I upload to the AEA Data and Code Repository?
Yes.
Licensing
What license applies to files made available through the AEA Data and Code Repository?
You as a depositor choose a license. The AEA suggests Creative Commons Attribution International 4.0 (CC-BY) for data and any documents, and the modified BSD license for software and code. However, authors are free to choose other licenses as long as these allow for others to use the data and code for replication purposes. If in doubt, contact the AEA Data Editor.
What to Expect
Will my code be run by the AEA?
Yes, within reasonable limits of time and computing resources, we will run your code and verify, prior to acceptance, that the results produced by your data and code correspond with the publishable results in your article.
How does the AEA test that the data and code is reproducible and replicable?
Generic guidance is provided at the Social Science Data Editors' Guidance. We use this template to guide our replicators. See an example report.
We assess:
- software availability
- data availability
- code availability and clarity
- needed computational resources
- time needed to acquire or use all of the above, and conduct the reproducibility check
When some of the conditions are not met with our own resources, we may ask others to conduct a reproducibility exercise for us because they are experts or have access to the required software, data, or computational resources.
Our protocol is outlined here.
Also see various points under restricted-access data.
Uploading
Can I use other archives or data repositories?
Yes, as long as they are considered "trusted" archives or repositories (see guidance). The AEA Data Editor will assess suitability of any such repositories and archives.
My data is made available on Dropbox, OneDrive, Sugarsync, or my personal website. Do I need to do anything else?
Cloud storage providers, commercial or otherwise, are not “trusted” archives or repositories. You will need to upload your data to the AEA Data and Code Repository.
We already use git, svn, GitHub, GitLab, or BitBucket, etc. Do you facilitate integration of existing version-controlled code to the AEA repository? Or is there planned functionality for linking out directly to such projects where they can be found online?
We are open to linking out to existing archives of code and data. However, GitLab and similar tools are not archives. See the relevant section on Social Science Data Editors pages.
In all cases, a proper archive needs to be created from the git repository:
- If using Github, you can follow this guide on linking to Zenodo.
- If depositing at the AEA Data and Code Repository, you can easily do the following steps:
- create a release on Github, Gitlab, etc.
- download the ZIP file associated with that release
- (strongly suggested) remove the initial directory level: unzip the ZIP file, move down a directory, re-zip (command line one-liner for Bash: unzip aea-de-guidance-20200129.zip && pushd aea-de-guidance-20200129; zip -rp ../upload.zip; popd)
- Import the ZIP file (now called upload.zip) into the AEA Data and Code Repository project
The above guidance does not preclude linking out to live code on such platforms. At present, we have no concrete plans, but we are considering various ways to make articles and their landing pages more informative. In the short term, treat a Github repo as any other URL and cite it. For example:
Lars Vilhuber. 2020. "AEADataEditor/aea-de-guidance: Unofficial guidance for authors [Github]". https://github.com/AEADataEditor/aea-de-guidance. Accessed on March 11, 2020.
You can also elaborate more freely in the README.
How do I cite my data and code deposit?
A link to the data and code deposit will be automatically added to the article page on the AEA website.
If the data is original (you collected or otherwise uniquely prepared the data), you should also add a data citation, pointing to your data and code deposit. If you are depositing the data at the AEA Data and Code Repository, we provide a tool to generate the citation. If elsewhere, all trusted repositories provide a suggested citation after publication of the data.
Should my data and my code be in the same deposit?
In general, yes. However, if you believe that you will reuse the data as is, and in particular if you would like others to also use the data, we strongly suggest creating a separate data deposit at a data repository. In certain cases where the data is original (you collected the data) or otherwise of high value (you made substantial usability or other improvements to the data), we may suggest that you deposit the data in their own, unique data deposit, to better highlight and make accessible the data.
This deposit does not need to be at the AEA Data and Code Repository—it can be at any trusted repository. See the Social Science Data Editor's Guide to Data and Code Hosting. Once deposited and published, the data should be cited in your manuscript in accordance with the AEA Reference Style.
Software Questions
Some econometrics papers might be accompanied by a software package, for example, R or Stata (perhaps published on CRAN or SSC). What about surfacing references to associated packages more prominently?
First, packages on CRAN and the Statistical Software Components can be cited. AEA citation guidance is currently silent on software components, but it is not wrong to cite them and other disciplines do it regularly. CRAN in fact has elements of a "proper archive"; SSC does not. All R packages can generate a (BibTeX) citation. SSC packages have a suggested citation on the associated package page.
Second, it is possible to submit such packages to various journals, where they are reviewed and published with a DOI:
Finally, you should always verify with the package (author, description, etc.) whether there is a citation request or requirement associated with the "license" of the package. As part of our reproducibility checks, we may find these, and non-compliance can lead to delays.
Do you support Docker, Jupyter, etc.?
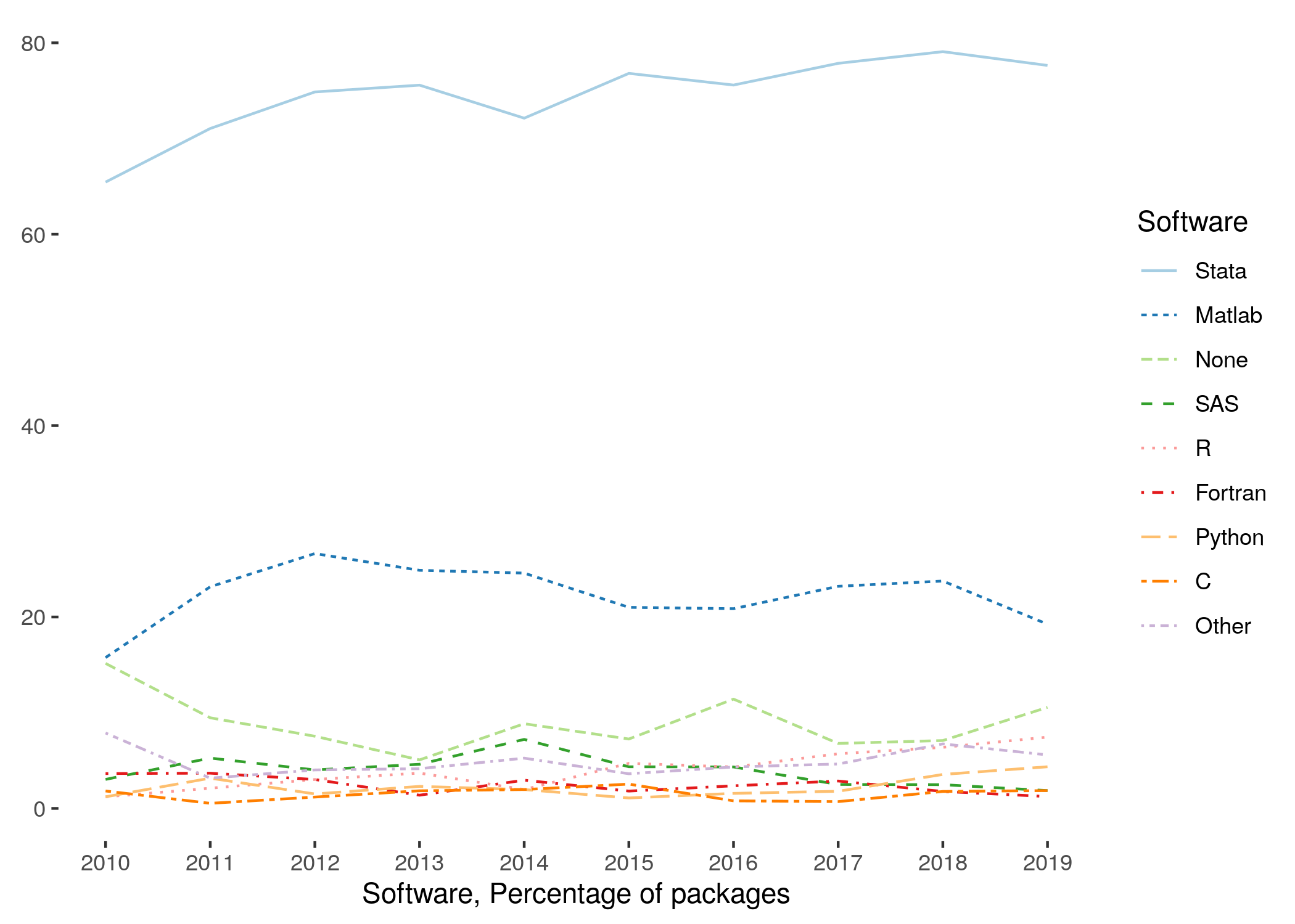
The simple answer is yes. The key is to make it clear in the README how to run the software. Most economists know how to run Stata, MATLAB, and probably can figure out how to run R or Julia even if it is not their native programming environment. For software that is less standard (GIS, SQL databases, Docker, Jupyter notebooks, cloud-based compute clusters, etc.), we suggest pointing to (citing) an introductory tutorial available on the web in the README and providing a barebones set of instructions on how to get started. The picture below illustrates the software that can be considered to be "common" among economists (source: Vilhuber, Turrito, and Welch. 2020. "Report by the AEA Data Editor." DOI: 10.1257/pandp.110.764).
Restricted-Access Data
My data has identifiable person or firm/establishment information, and I want to control who has access to it. Can I use the AEA Data and Code Repository?
No. You will need to either remove the identifiable information, or make the data available at archives that support the relevant access controls. You can find additional guidance here.
I have been told by the AEA Data Editor to remove PSID data from my submitted materials. What do I do?
Authors are not allowed to post extracts of PSID data online, with one exception: they are allowed to deposit their data extracts and/or their derived data in the PSID data repository. Doing so allows authors to remain in compliance with the PSID’s Terms of use. Any other deposit, including in the AEA Data and Code Repository, is not allowed.
Somewhat confusingly for some users, the PSID repository is also hosted at openICPSR, just as the AEA repository. However, the two repositories do not have the same Terms of Use, and are distinct.
In order to comply with the PSID Terms of use, you should do the following:
- Create a new deposit at the PSID repository. Be sure to choose the PSID repository! (it can be confusing)
- Give the deposit the title "Supplementary data for: (TITLE OF YOUR PAPER)"
- Upload only the data files related to PSID
- Fill out as much of the additional information as you can, including the Time Period covered.
- Go through the process to "Publish" this data
- You will obtain a DOI that looks somewhat like https://doi.org/10.3886/E123456V1. Copy that down.
- Return to your AEA deposit
- Delete your PSID files that you just uploaded to the PSID repository
- In the "Related Publications", add the DOI you just copied down as a "related" publication
- Update your README and any other instructions to identify the DOI for the files that a replicator must download separately in order to reproduce your results.
- Don't forget to cite the DOI you copied down in your manuscript!
- Per the PSID website, you should include the following acknowledgement:
The collection of data used in this study was partly supported by the National Institutes of Health under grant number R01 HD069609 and R01 AG040213, and the National Science Foundation under award numbers SES 1157698 and 1623684.
- PSID also wants you to send copies of the manuscript to them, or add the DOI of your AEA article to their bibliography. Please do so, supporting them!
Access to the data I used is restricted. Surely you won’t be able to run the code. Is that a problem?
The Editor needs to be alerted to such situations at the time of submission. In all such cases, we still ask you to provide the code, and a description of how the data can be accessed (Data Availability Statement). We may test the access protocol prior to acceptance, and we may ask for support by third parties in running the code you provide. It is likely that this will not always be possible. The ultimate decision about whether to go forward with the submission, and whether to accept an article rests with the journal’s Editor or Co-Editor.
I use confidential data. I am allowed to provide the data to the Data Editor for the purpose of replication, but you are not allowed to publish the data. How do I proceed?
First, all sharing - whether privately with us, or publicly through the data publication process - should be in compliance with all IRB rules, data use agreements, etc. We will never ask you to share data that you do not have the right to share with us or anybody else.
Second, there is a difference between sharing with us, and publishing the data. We can accept private data sharing for the purpose of replication, conduct our reproducibility checks, and delete the data provided. You are in control of the publication of any data (though it has happened that we have had to point out to authors that they do not, in fact, have the rights to publish data that they were going to publish).
Third, the inability to publish the data does not absolve you from creating an archive of the data as it was used for the article. This archive, for private/confidential/proprietary data, should remain private - on your own systems, or appropriate university archives. But it must exist, so that you can reliably answer queries from authors in future years.
How should you proceed?
The best way to think of this is as a set of layers. Your working directory WD, from which you derived the tables and figures in the paper, is composed of confidential data CD, non-confidential data NCD, and programs/code P (and possibly temporary files TF). So WD = CD + NCD + P + TF. For the purpose of replication archives, you should create two archives:
- A.zip : contains NCD and P
- B.zip : contains CD
You should then test: create an empty directory, unpack the two archives, and verify that they are sufficient:
(unzip A.zip) + (unzip B.zip) == NCD + P + CD == WD - TF
You should then import A.zip into the openICPSR archive, and ensure that B.zip is properly and securely archived, in compliance with all rules that you are subject to.
You can provide B.zip to us for the purpose of replication, but B.zip would not be published.